
Search Steps
Search Steps abstract the searching process, you can define different steps to get help users get the right results.
You can use a query classification step to select the correct search step. Or, if you're using tool calling, you can have the LLM select the correct search step.
Search Types
Standard
This is the standard BM25 keyword search. This is a general purpose algorithm that's good when the priority is returning everything that matches the query terms.
This is typically good for compliance scenarios.
Cosine Similarity
This is a type of semantic search. It uses dense vector embeddings and cosine similarity to compare a search to a set of documents.
To scale cosine similarity a keyword search is performed first to gather relevant items. These items are then reranked using cosine similarity.
You can limit the number of items reranked by defining a bucket size. This also helps scale the cosine similarity as it limits how many results go through it.
We recommend defining a bucket size if a keyword search returns more than a few thousand items.
When using a bucket size, the rerank is performed on the best matches defined by the keyword search. Items not reranked have their score normalised so they appear after anything reranked.
Documents and data must be enriched with dense vectors to use cosine similarity.
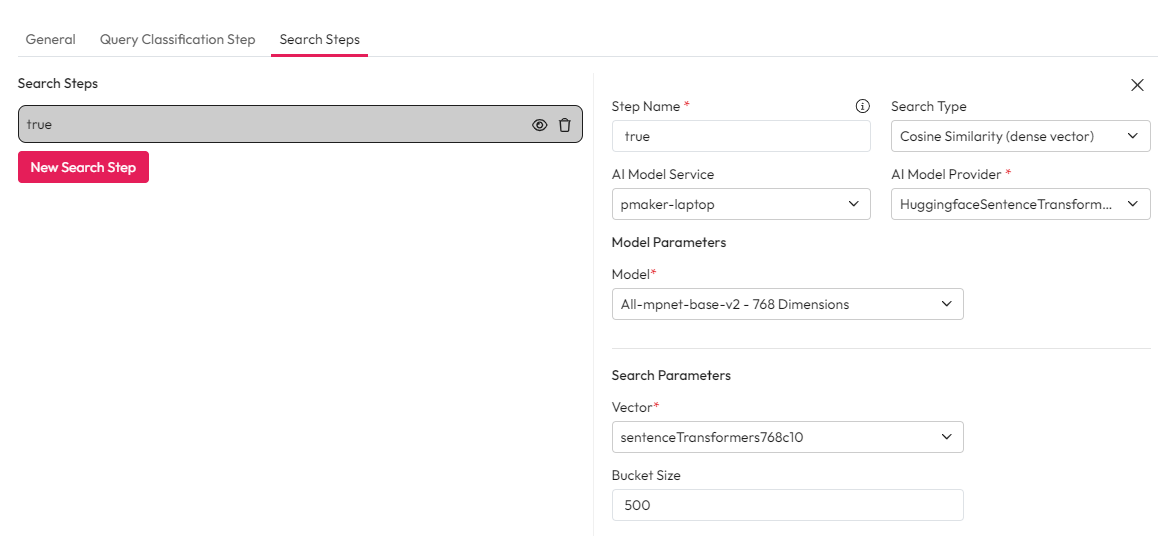
Enrichment for Cosine Similarity
There are 3 key steps for enriching with cosine similarity. See our guide on creating vectors for more information.
Create one or more Vector mappings in the Control Hub. These dimensions map to the AI model you are using.
Apply the vector to the sources you want to use in this search flow.
Create an enrichment step using AI Enrichment Service to compute and apply dense vectors.
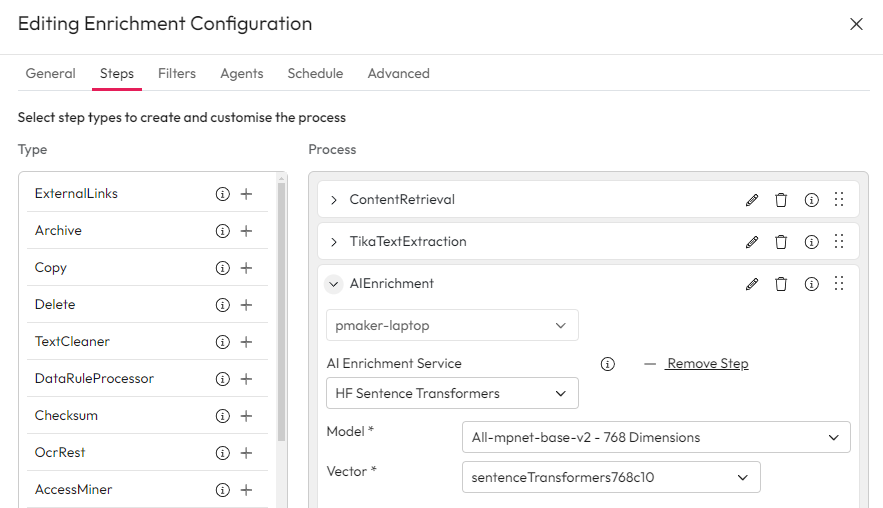
Note that you must make sure the vectors match across enrichment and search steps. For example, if you have uses a QA model at enrichment time, and you have a QA search step (i.e. you are using the query classification ask a question model), then you must use the same vectors.
Rank Features
Rank Features are a type of sparse vector. They map features or terms to weights that reflect their relative importance.
At search it compares the vector of the users search to the vectors in the results. It use the weights in the users query against the weights in the results to determine relevance.
To use rank features you will need to enrich your documents and data with sparse vectors.
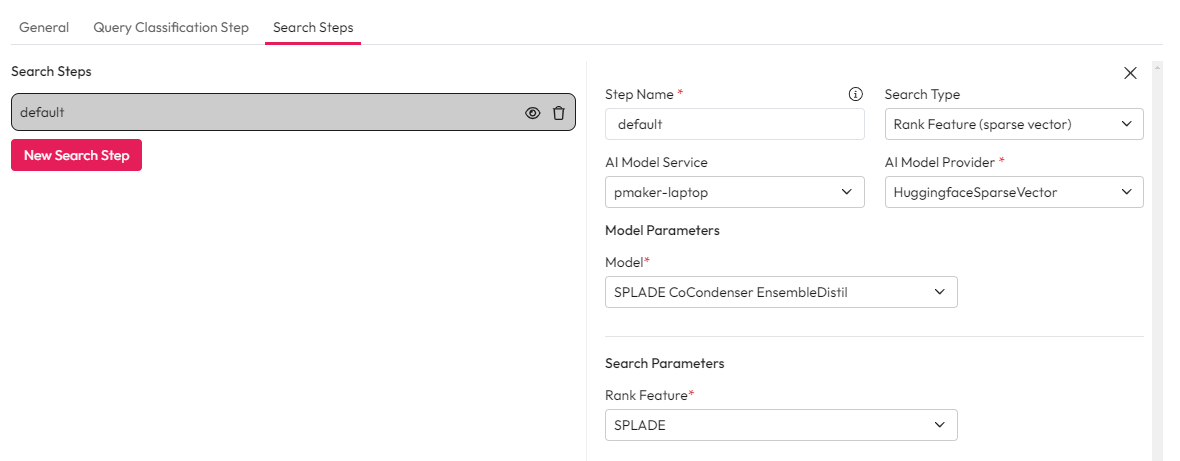
Enrichment for Rank Features
There are 3 key steps for enriching for Rank Features. See our guide on creating rank features for more information.
Create one or more Rank Feature mapping in the Control Hub.
Apply the Rank Feature to the sources you want to use in this search flow.
Create an enrichment step using AI Enrichment Service to compute and apply sparse vector.
Configuration
General configuration includes:
Step Name - The name of the step. If you have used query classification, this should be the same as one of the classification model labels.
Search Type - The type for the search step.
AI Model Service - The model service that is running the vectorizer provider.
AI Model Provider - The provider to use. You will only shown vectorizer providers.
Model - The model to use. Make sure you select the right model and that it matches the model uses at enrichment time.