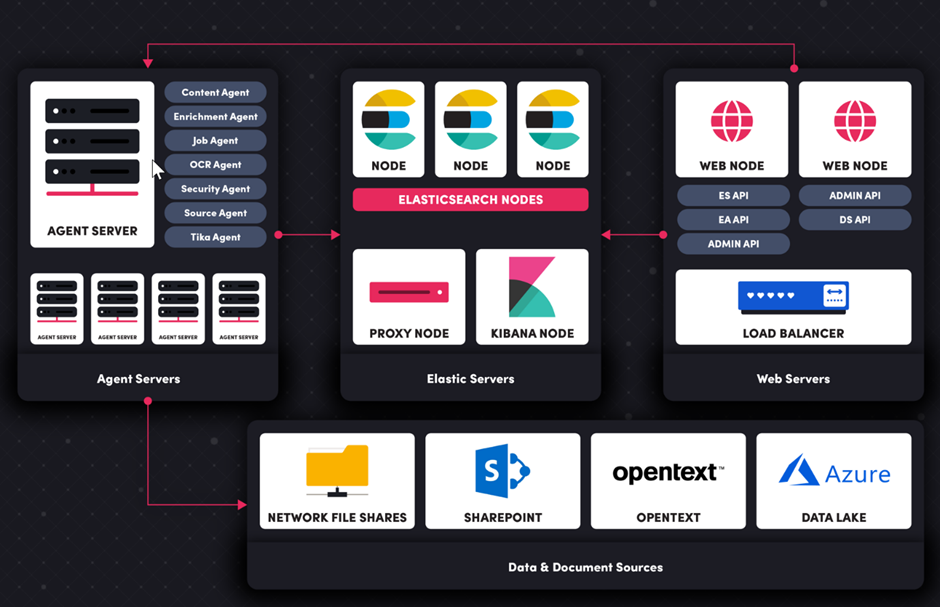
This schematic illustrates an example architecture for Workplace AI.
| Security Agent | Responsible for synchronising users and groups from the credential stores. It is also responsible for servicing authentication requests. |
| Source Agent | Connects to source systems to discover new, modified and deleted data and documents. It also fetches data and documents for enrichment and when users want to preview a document. |
| Content Agent | A support service for the Source Agent. It handles thumbnails, caching, proxying document & data fetch and preview requests. |
| Enrichment Agent | Runs enrichment on data and documents stored within Workplace AI. It runs the configured pipelines, each containing one or more enrichment steps. For example, document classification, NER or image recognition. |
| Job Agent | Runs maintenance and other jobs that the platform requires to be run. For example index backup, recommendations, and notifications. It may also run customer specific scripts. |
| OCR Agent | Responsible for running one or more OCR engines. Out of the box IronOCR is provided, but plugging in other engines such as ABBY Reader is supported. |
| Migration Agent | Runs migration jobs which move documents and data between systems. |
| Tika Agent | Converts documents from their native format to plain indexable text. This is used by the enrichment agent (Tika Text Conversion Step). |
This schematic illustrates an example architecture for Workplace AI.