JSON Data Loader
Introduction
If you want to load data structured or unstructured from a JSON file use the JSON data loader.
To complete this loader you must have a completed Data Model created to match this data. The Data Model must be published to show in the creation of this Data Loader.
Input Files
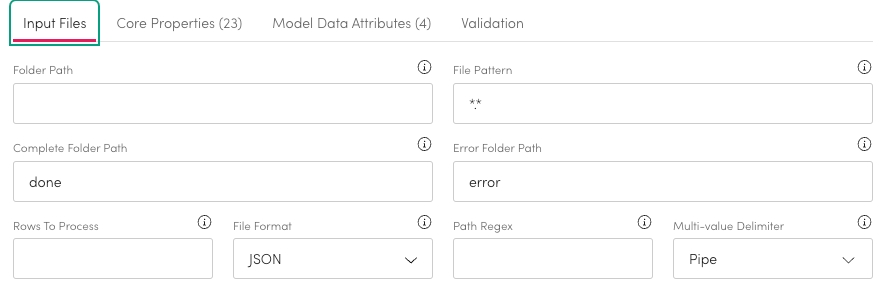
In order to find the files to load you need to complete the Input Files tab.
Enter the location of the file into the Folder Path.
Enter a naming pattern into file pattern.
You can use a wildcard as part of a naming pattern to load multiple files.
Entering *.* will load all JSON files from that Folder path.
When a file has finished loading you can choose what folder the completed file goes to. Add the name within Complete Folder Path.
By default this is set to done.
When processing a file if an error occurs you can choose what folder the file goes to. Add the name within Error Folder Path.
By default this is set to error.
This allows you to find the files that have failed and investigate why.
You can run a limited number of rows as a test for processing. It will run the process on that number of rows and they will be processed to Insight Engine. Enter the number of rows that should be processed to Rows To Process.
If left blank all rows will be processed.
You can choose between JSON or JSON Line files in the File Format field.
Enter a Path Regex to pinpoint a specific attribute of a file to scan.
If a file is using something other than Pipes to separate multi-values you can choose it from Multi-value Delimiter.
The file will not process unless the delimiter is set correctly.
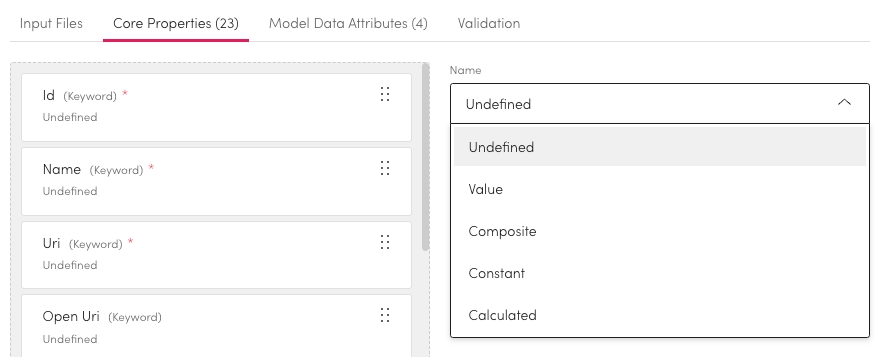
Core Properties
For each file property you can choose its type. By default all properties will be undefined, you can choose between:
Undefined, Value, Composite, Constant and Calculated. Fields marked with a red asterisk * require a definition.
Select the property you want to define.
Choose the property type from the list on the right.
Depending on the property type selected you will need to define more.
Undefined
These fields will not be mapped.
Value
Select the Column to map this field to.
Composite
Create a string using text and numbers within curly brackets {}. Once you have added the components of the string you can select the inputs that will sit in place of the numbers once processed.
Constant
This will populate a field with the same text value no matter what.
Calculated
This will enter either the current date or Current date and time into a field.
This is the time of the load running.
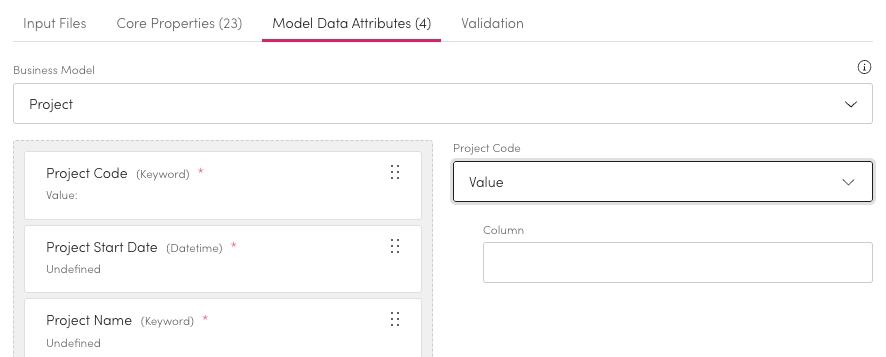
Model Data Attributes
To connect a field from the file to an attribute in the data model you need to run a file with 3-5 data rows in to the validation.
This will pull in all the field labels from the file. Once run you can then complete the mappings the same way as with core properties.
Select the relevant Business Model.
Select the property you want to define.
Choose the property type from the list on the right.
Depending on the property type selected you will need to define more.
Undefined
These fields will not be mapped.
Value
Enter the Column name to map this field to.
Composite
Create a string using text and numbers within curly brackets {}. Once you have added the components of the string you can select the inputs that will sit in place of the numbers once processed.
Constant
This will populate a field with the same text value no matter what.
Calculated
This will enter either the current date or Current date and time into a field.
This is the time of the load running.
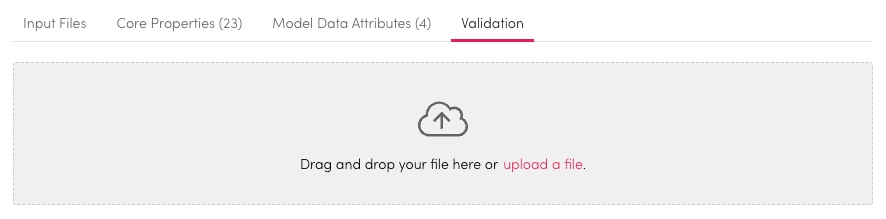
Validate
Once all features are defined you can run the test file once more. You can then check the fields and data are mapped correctly. If they are not go back to Model Data Attributes or Core Properties to correct them.
Drag and drop a file for validation or select Upload Here to find a search for a file.
Once loaded select validate.
This can be run multiple times until you are happy with the selections.
Select Save when you are done.