
Technology Methods
Extractive Methods
All extractive methods rely on the identification of features: characteristic words or phrases critical to the meaning of the text. Phrases are then scored and the highest scoring are combined into a summary. Approaches vary in the features they choose to identify, and in the scoring methods used to rank them.
Commonly used features include [2], [3]:
Content words: typically nouns uniquely occurring frequently in this particular text (tf-idf)
Title words, and those in headings and sub-headings
Sentence locations: first and last sentences of the first and last paragraphs
Proper nouns (this may involve Named Entity Recognition)
Uppercase, italic, underlined or bold words
Cue phrases: these contain special terms such as “in summary” or “in conclusion”. This can also include domain-specific terms of interest
Similarity between sentences and to the whole textual content. This indicates repeated phrases.
Which features are used is dependent on the domain, scoring algorithm and format of the input text. For example, scientific papers in one discipline tend to use predictable language which can inform cue phrases, but works of fiction are far less uniform. Identification of italic, bold or underlined terms requires knowledge of the document’s markup; applicable to web pages and some documents but not necessarily text extracted from a PDF or web form.
In the following subsections, we will describe some of the scoring algorithms used for identifying significant sentences.
Term Frequency-Inverse Document Frequency (tf-idf)
Term Frequency-Inverse Document Frequency (tf-idf) is one of the most common text scoring algorithms and is popular with search engines for ranking results. It assigns a higher score to terms that occur frequently within a text while occurring infrequently in other texts within a collection. This allows the most unique terms to a document to be identified [4]. Tf-idf is most commonly applied to single-word features, but can be expanded to phrases if they are normalized, e.g. similar phrases are converted to standard format that can be considered equivalent within the document corpus.
Graph Theory Representation
Documents can be represented as an undirected graph, with sentences as nodes and vertices joining similar phrases (by cosine/string similarity, or another metric) [5]. The information gained by this approach is twofold: Firstly, clusters of joined nodes represent topics, and can be used either to summarize a particular topic, or the document as a whole if representative sentences are chosen from each cluster. Secondly, nodes with high inter-cluster relations can be considered relevant to multiple topics, and therefore of greater use in a document summary. In contrast to tf-idf, this approach can be applied to sentences of any length and does not require pre-processing, as the similarity scoring makes normalization redundant. The popular summarization algorithm TextRank is based on these methods [6].
Concept-based Clustering
There are various topic and concept extraction tools such as WordNet [7], HowNet [8] and Lingo [9]. Topic clustering is more immediately useful for providing keywords representative of a text, e.g. for suggesting related topics in a search context. However, it can be used to process sections of a longer text, which are analyzed independently for focus and relevance to a particular topic and used to form the basis of a summary. In this manner, concepts instead of words can then be used in a scoring algorithm to produce the final summary [3], [10]. Topic-based approaches are conceptually similar to those used in the more advanced abstractive summarization methods, discussed in the next section.
Abstractive Methods
Abstractive approaches have seen a surge in research due to the development of deep learning techniques for Natural Language Processing (NLP). Summarization of this type offers improved readability and the potential for more efficient knowledge conveyance. NLP is most heavily employed for speech recognition and video captioning where there exists a 1:1 mapping between input and output signals, and therefore the requirement for conceptualizing the text is limited. For a summarization application, the text must not only be read, but be algorithmically understood and the most significant pieces of information interpreted into a coherent output.
Structure Analysis
Most abstractive techniques condense a text corpus into a uniform format based on the structure of input sentences. Sentence Fusion [11], developed using news articles, aims to combine several sentences discussing a common theme into one. A tree structure is built describing the sentences based on the dependencies between constituent words. The figure below is the dependency tree describing the sentence “The IDF spokeswoman did not confirm this, but said the Palestinians fired an antitank missile at a bulldozer on the site.”
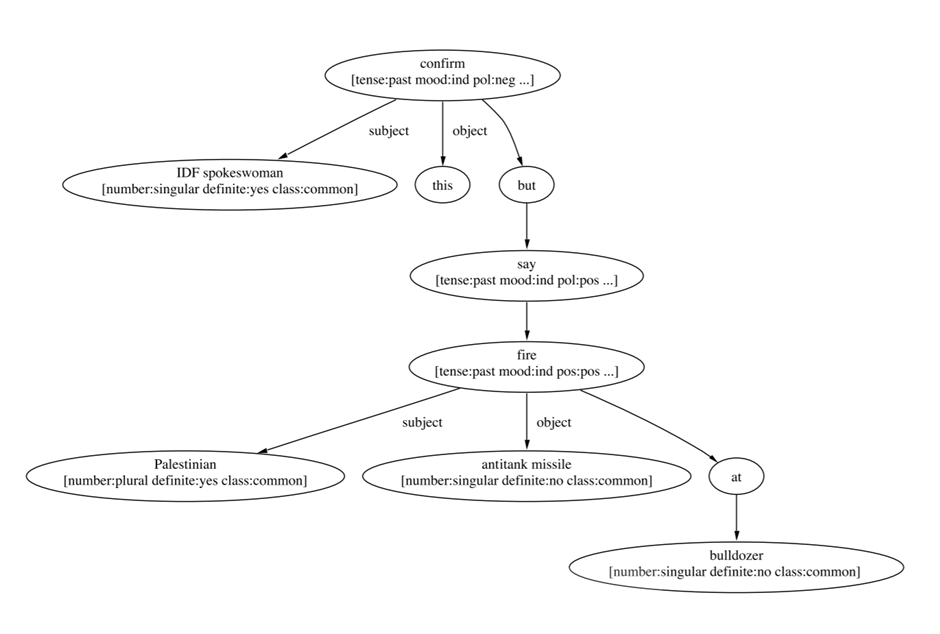
The trees reveal branches through the text corpus with highest inter-sentence connectivity, and suggest summarization pathways containing as much of the original information as possible. Output sentences are then constructed using semantic rules. The transferability of this technique to domains other than that of news articles is highly dependent on the focus of the input text, as effective summarization requires strong common focus on the overarching theme.
Data structure translation
The identification of topic-related information is common to all summarization methods, and is usually comprised of techniques similar to those discussed previously (linguistic structure, common words, scoring based on position or mark-up qualities). The synthesis of new sentences depends largely on the choice of data structure for storing them, and several inventive solutions have been proposed distinct from dependence trees. GISTEXTER [12] builds a database of sentences by topic with a focus on distinctness, entries from which are then added to a summary. The Lead-and-body-phrase method analyses the head and body of sentences separately to insert or substitute phrases based on the volume of new information each successive sentence contributes to an existing stem. Opinosis [13] is a graph-based summarizer focused on identifying redundancy in the text corpus, similar to the extractive method discussed previously. It is regarded as a “shallow” abstractive method as it relies heavily on the input text’s similarity scored to identify both phrases that contribute heavily to the main topics and where redundancy in the output can be minimised. For the reason the output is often close to the phrasing in the input, but with semantic enhancements for readability and interpretability.