
Adding or Changing Entities, Metadata
A very common task that you can use a Python enrichment step to do is add or edit metadata or entity values.
To do this, first ensure the metadata item or entity exists in Control Hub and is of the right data type. For example:
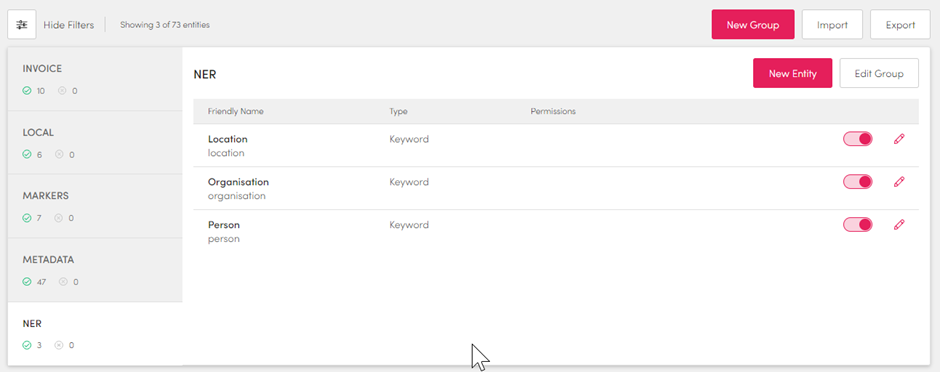
Let’s edit our example to add an ‘ner person’ entity (note that entity groups are always camel case and not upper case as shown in Control Hub).
Note the line that adds the ‘ner’ group and then adds the ‘person’ list to it.
We can also test this from main by setting up our work item as required with entities.
If we add a new document, or update the test document and re-run the crawl and then re-run the enrichment pipeline we should see the following in Aiimi Insight Engine.
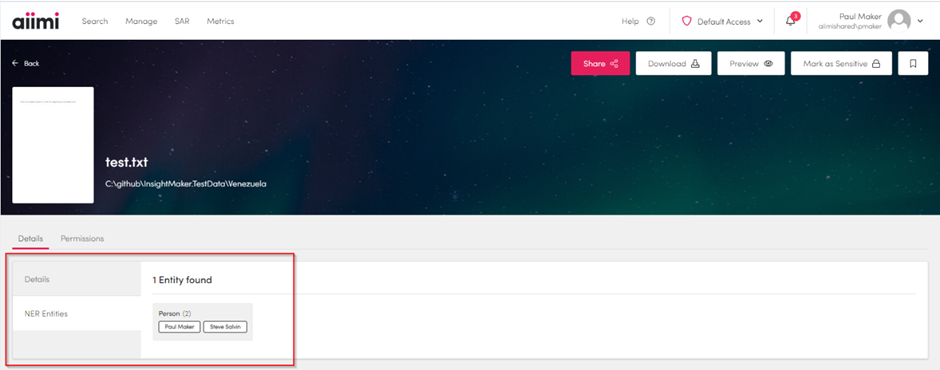
Here we can see our ner person entities in Aiimi Insight Engine document details page for the search result.